Day 1
- try to embrace
spark.sql(...)
Day 2
-
HIVE METASTORE (?)
-
deltalake managed and external table
- managed → if you dropped table, both parquet and table metadata is dropped
- external → only table metadata is dropped
-
Deltalake described table
DESCRIBE DETAIL '/data/events/' DESCRIBE DETAIL eventsTable DESCRIBE [SCHEMA] EXTENDED ${da.schema_name}_default_location; -
Create table
CREATE SCHEMA IF NOT EXISTS ${da.schema_name}what is the difference with
DeltaTable.createIfNotExists? -
Define table schema while creating table is recommended
-
SQLite → a database that use local file system
-
Using
CREATE OR REPLACE TEMP VIEW {table_name} ({all_col_schema})to read and infer schema before creating table or you can useCREATE OR REPLACE TABLE sales_unparsed(find out more about this and CTAS) [link] -
You can enrich your delta table by adding more metadata information

- you can use
pyspark.sql.functions as Fto get theinput_file_nameorcurrent_timestampto enrich your table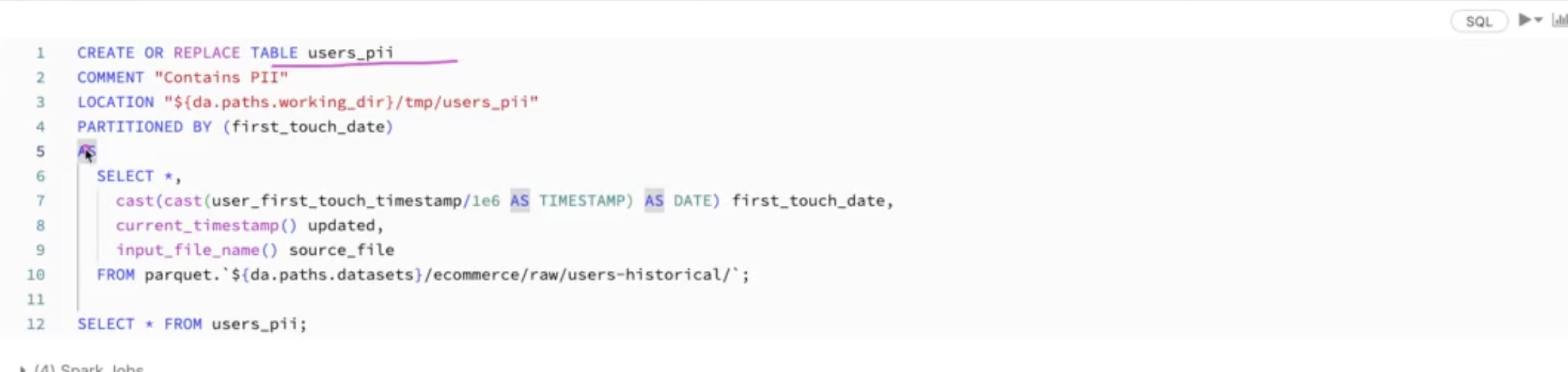
- you can use
-
AS A BEST PRACTICE, DONT USE PARTITIONING IN DELTALAKE IF THE TABLE IS SMALL
-
You can use DEEP or SHALLOW clone of delta table source to use it for model development or testing.
-
Avoid to use Spark RDD, just use the higher level API because it is included Query optimization
-
You can use
sparkdf.schemato get the schema and use the schema to create another table -
df.collectget all data from all executor to driver -
you can use
df.creteaOrReplaceTempViewto use a sql spark API which create temporary table in memory -
Spark dataframe is immutable
-
count(*)count null value, usecount(colname)to skipped null value- conver from timestamp to date format
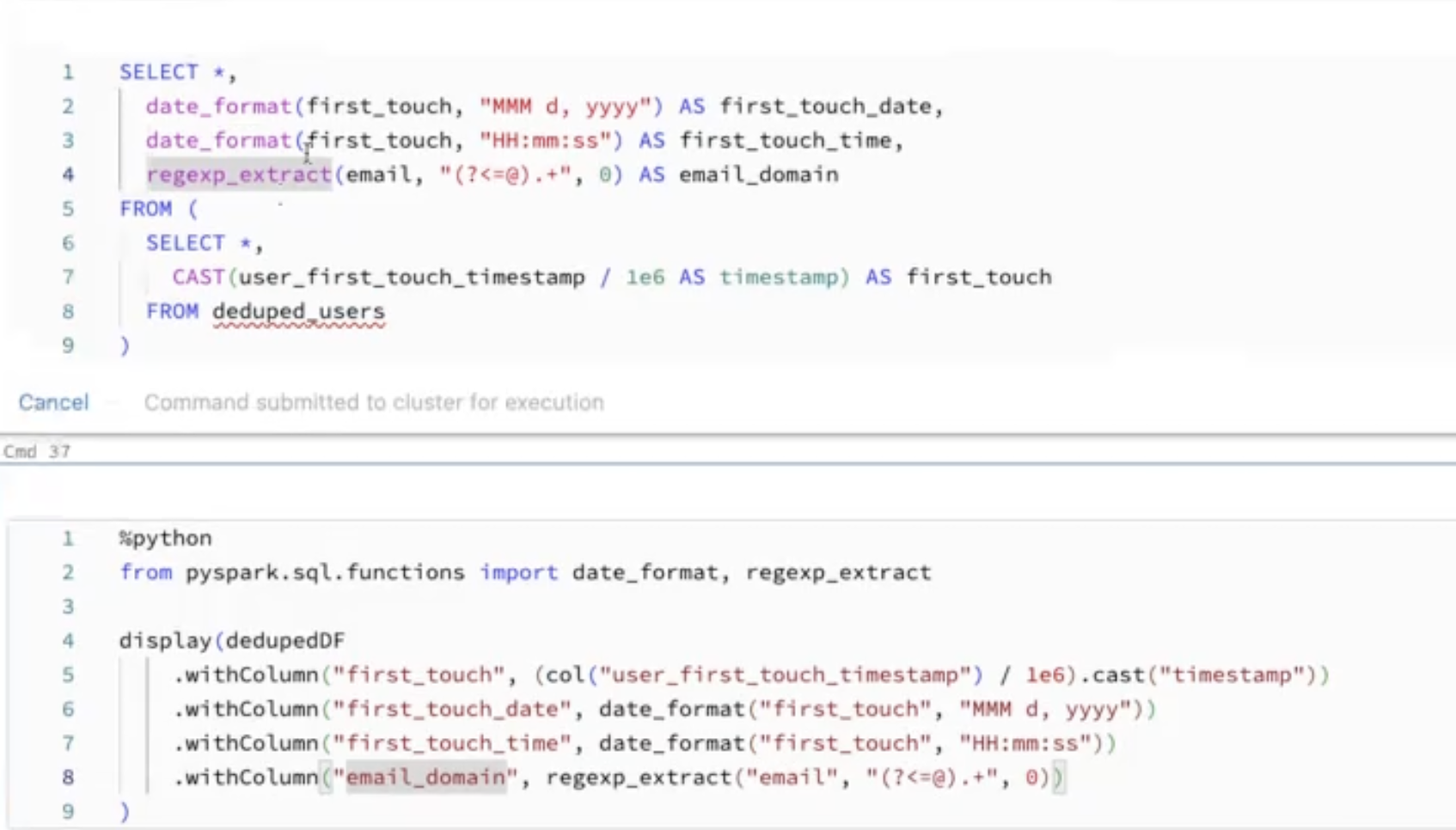
- conver from timestamp to date format
-
you can use
.to access nested data -
infer all table or dataframe to pyspark native schema
-
The reason why many spark schema use struct to reduce the memory usage, if you want to explode consider to select only needed column. explode dataframe is expensive!
Day 3 (20230419)
-
Incremental data ingestion with Auto Loader
-
To enable schema evolution for future need, you need you track the schema evolution (ref: deltalake schema evolution format)
-
In order to avoid data throw due to unmatched schema or data type you can create a column called
_rescued_data(check how to use) -
schema_hints
-
checkpoint is really importance in structure streaming
-
Streaming should be
- High available
- Reply-able
- Durable
- Idemponent
-
You can view the streaming dataframe in streaming manner using
readStream(...).createOrReplaceTempView(). the you can check or applied the data transformation using spark sql API. Then you can write it back usingspark.table("tempViewname").writeStream(...)(see. DL 6.3L)(spark.readStream .table("bronze") .createOrReplaceTempView("streaming_tmp_vw")) %sql SELECT * FROM streaming_tmp_vw for s in spark.streams.active: print("Stopping " + s.id) s.stop() s.awaitTermination() # operation %sql SELECT device_id, count(device_id) AS total_recordings FROM streaming_tmp_vw GROUP BY device_id -
Streaming
trigger(availableNow) -
Streaming
trigger("once")is useful to run the program once you need. Because it store the checkpoint, so next time it run, it will get the data from the last checkpoint. But its recommended to usetrigger("availableNow").
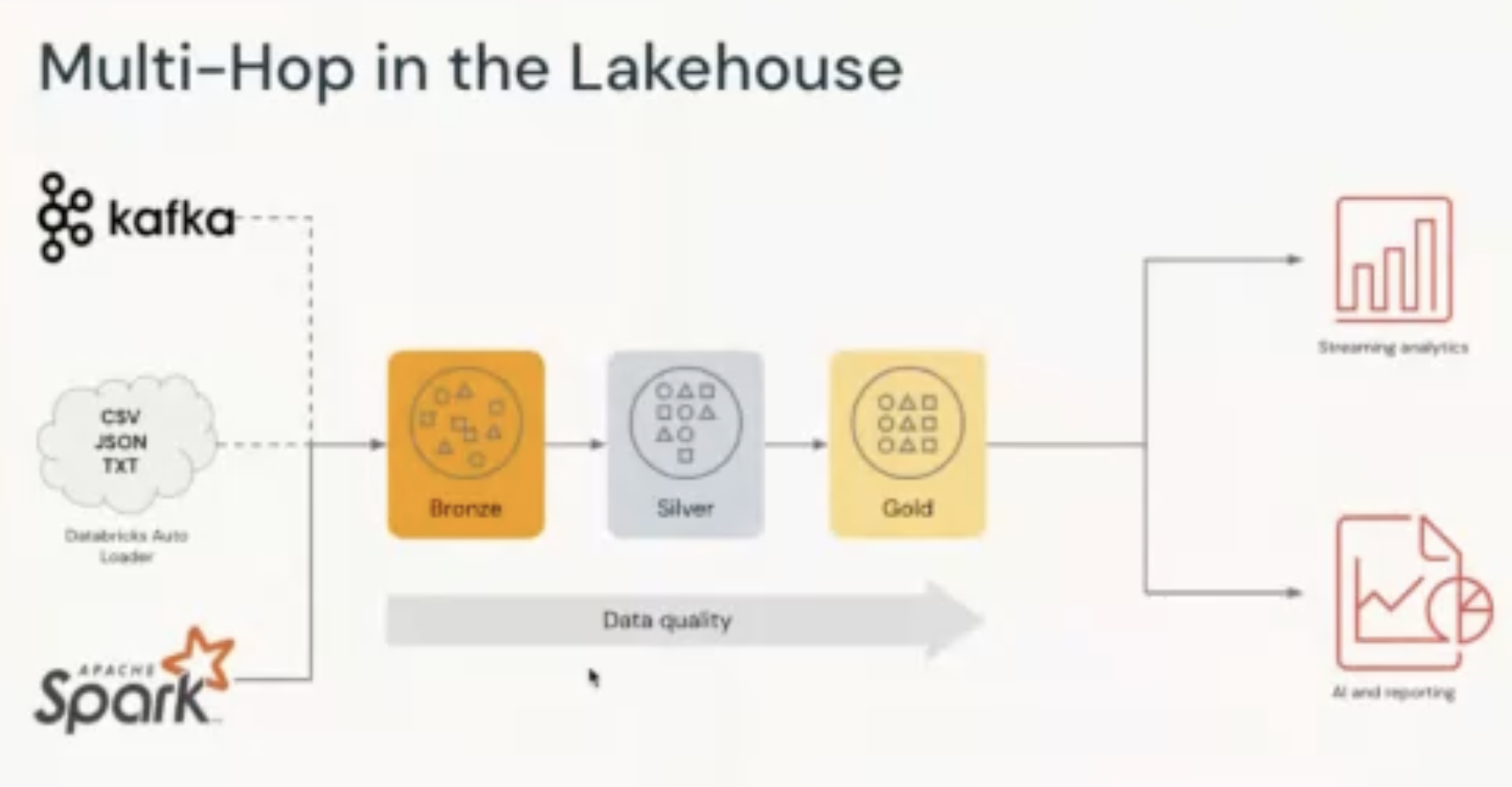
MULTI-HOP Architecture