-
make a new useradd for hadoop master
useradd -m its -
give the root access using visudo
its ALL=(ALL:ALL) ALL -
change the hostname using
sudo hostname <hadoop-master> -
download openjdk 8 or 11 and extract the tar
-
Move extracted folder to
usr/local/or/opt/so everybody can access java -
add env variable and put in bashr also add path
export JAVA_HOME=/usr/local/jdk-18.0.1.1 export PATH=$PATH:$JAVA_HOME/bin -
mapping nodes
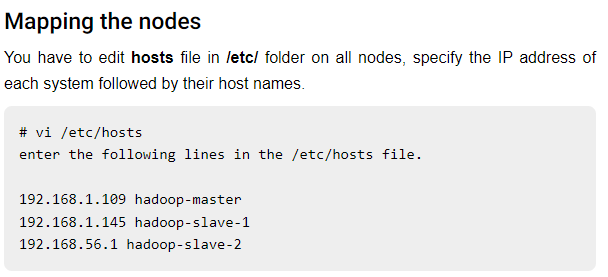
-
configuring ssh key to all slave
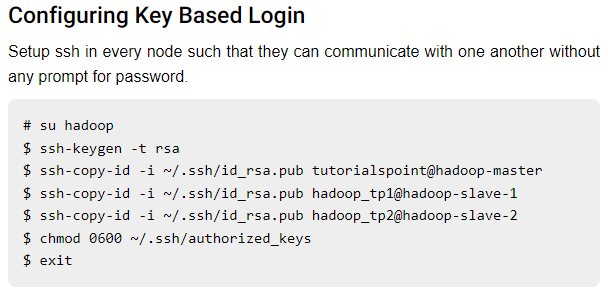
-
download and install hadoop (untar using
tar -xzf <.gz.tar file>-
hadoop mirror link
-
-
configure hadoop
- hadoop .xml file can be found in
hadoop/etc/hadoop/

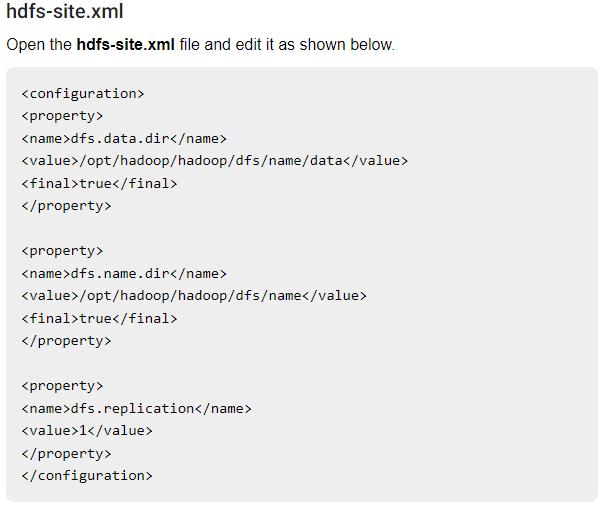
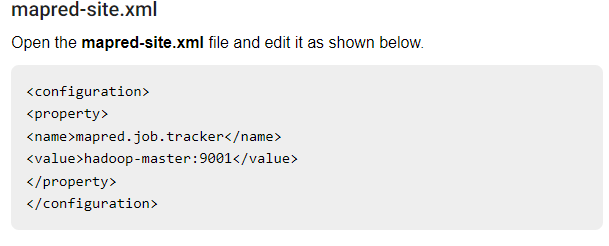
- hadoop .xml file can be found in
-
permission problem and copy hadoop to another node
- in order to resyn, you need to mkdir hadoop in slave node with
chown -R its hadoop
sudo chmod -R 777 optrsync -avzhP /opt/hadoop/hadoop-3.3.3 hadoop-slave-01@host:/opt/hadoop - in order to resyn, you need to mkdir hadoop in slave node with
IMPORTANT
-
don’t forget to set up uniform
/etc/hostfor master and all nodes -
to format or restart Hadoop make sure you use
bin/hdfs namenode -format -
every restart make sure to remove
dfsdirectory -
the
hadoop/etc/hadoop/workerin all nodes shoud behostnamedon’t uselocalhost -
check dir
chownorchmod -
without avro 16mins → 6.5mb
-
check hadoop directory
bin/hdfs dfs -ls / -
if the hadoop:9000 is not in
nestatplease check thedfsdir. hadoop:9000 only working if thedfsdir is available (this behavior usually happens when you remove thedfsafterbin/hdfs namenode -formatcommand is executed). -
if one server/datanode is down, use
hdfs --daemon start datanodein the node. -
ensure pyarrow installation
-
if error below, check another version of JDK
ERROR Cannot set priority of resourcemanager process at <> -
when the datanode is not detected or the datanode is now shown in web UI, please remove the dfs directory in that datanode and stop, format, start again
-
if error below happen → in hadoop master node make a dir
bin/hdfs dfs -mkdir /rawandbin/hdfs dfs -chmod -R 777 /rawCaused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=root, access=WRITE, inode="/raw":its:supergroup:drwxrwxr-x -
if error below happen → in the client set the env variable
export HADOOP_USER_NAME=<username at master>22/07/26 03:41:44 ERROR MicroBatchExecution: Query [id = 81b7eb6c-a753-4f69-904e-6ed1af5e0721, runId = a9b235df-e53a-4ef6-a02d-b22b9f8fbd2d] terminated with error org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=WRITE, inode="/":its:supergroup:drwxr-xr-x Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=root, access=WRITE, inode="/":its:supergroup:drwxr-xr-x
References
https://www.tutorialspoint.com/hadoop/hadoop_multi_node_cluster.htm
https://dlcdn.apache.org/hadoop/common/
hdfs-site-xml
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/hadoop/dfs/name/data</value>
<final>true</final>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>